Shift-JIS 트롤링
유니코드가 보급중이기는 한데, 일본이라는 동네는 갈라파고스를 좋아해서 여전히 독자규격을 많이 사용하고 있다. 오늘 이야기 해 볼 내용은 그 중에서 글자를 저장하는 방법, 코드페이지에 대한 내용이다.
컴퓨터에서 글자를 직접 처리하지는 못하므로, 글자를 숫자로 대응시켜야 하는데 이를 코드페이지라고 한다. C 수업 하면서 ASCII 테이블은 많이 들어봤을 것이다. 이건 영어를 숫자로 대응시키는 방법이다.
ASCII 테이블 및 그 확장 변형판들은 1바이트(=8비트)를 최소 구성단위로 저장된다. 8비트 영역은 저장되는 글자 및 제어문자에 따라 4개 영역으로 분할될 수 있다.
- CL (Control-LEFT) = 0x00 – 0x1F 제어문자 영역
- GL (Graphic-LEFT) = 0x20 – 0x7F 출력 가능한 문자 영역
- 0x7F DEL 은 제어문자이지만 GL 영역에 배정된다. 펀치카드에서 특장 글자를 삭제하기 위해 모든 칸을 다 뚫어버린 것에서 유래한다.
- CR (Control-RIGHT) = 0x80 – 0x9F
- GR (Graphic-RIGHT) = 0xA0 – 0xFF
여하튼, 오늘은 일본어 코드페이지 중 가장 많이 사용되는 Shift-JIS (CP932)에 대해 이야기해 보자.
컴퓨터에서 일본어를 표기하려고 표준화하던 1969년 당시, 처리량도 한정되고 어쩌고저쩌고... 이런저런 이유를 붙여서 가타카나만 표준화를 했다. 현대 일본어에서 사용하는 가타카나 46글자, 촉음 9글자, 탁/반탁음, 장음, 문장부호 5개 해서 63개를 쓰기로 한 것. 현재는 주로 AA 그릴 때에나 많이 사용되며, 싱글바이트 LCD에 일본어 출력할 때 가끔 볼 수 있다.
GL AREA
␠ ! " # $ % & " ( ) * + , - . /
0 1 2 3 4 5 6 7 8 9 : ; < = > ?
@ A B C D E F G H I J K L M N O
P Q R S T U V W X Y Z [ ¥ ] ^ _
` a b c d e f g h i j k l m n o
p q r s t u v w x y z { | } ‾ ␡
GR AREA
␠ 。 「 」 、 ・ ヲ ァ ィ ゥ ェ ォ ャ ュ ョ ッ
ー ア イ ウ エ オ カ キ ク ケ コ サ シ ス セ ソ
タ チ ツ テ ト ナ ニ ヌ ネ ノ ハ ヒ フ ヘ ホ マ
ミ ム メ モ ヤ ユ ヨ ラ リ ル レ ロ ワ ン ゙ ゚
이 63글자를 0xA0-0xDF 영역에 매핑하였다. 1바이트로 한 글자를 표기하면서, 디스플레이에서 영문자와 같은 폭을 갖게 되어 향후 '반각' 가타카나라고 불리게 된다.
여기에 0x5C BACKSLASH도 JAPANESE YEN 표기로 변경되고, 0x7E TILDE 또한 UPPER LINE으로 변경되었지만 대체로 별 문제 없는 것으로 간주된다. 여하튼 이러한 매핑방법은 JIS C 6220으로 일본 내 표준화 되었으며, 차후 JIS X 0201로 이름이 바뀌게 된다.
한 10년쯤 지나서 1978년, 컴퓨터 성능이 발전하면서 히라가나 및 한자도 코드페이지에 포함하려는 움직임이 생겼다. 근데 이게 한두 글자면 상관이 없는데, 한자가 들어가니 6천자가 넘어가는 글자를 포함해야 하게 된 것이다. 최대 256글자만 수용(?) 가능한 1바이트 코드 집합으로는 답이 없어, 하릴없이 2바이트 코드집합이 정의되었다.
2바이트니까 원리상 최대 65536개 글자를 정의할 수 있다. 물론 이 영역을 모두 쓰지는 못한다. Control 영역은 침범하기가 영 껄끄럽고, Grphic 영역에서 0x20 SPACE와 0x7F DEL 또한 특수문자 취급이니 이를 제외하면 0x21-0x7E 범위에서 총 94개 값을 쓸 수 있게 된다. 여기에서 94x94 테이블이 유래하게 된다. SPACE와 DEL까지 쓰면 96x96 테이블이 되는거고.
이에, 선행 바이트 기준으로 다음과 같이 테이블이 나오게 된다. 참고로 여기에서 정의된 글자들은 2바이트 표기를 사용하며 화면상에서도 영문자 두 글자 공간을 차지한다. 표준에서는 "한자집합漢字集合"으로 정의한다.
- 0x21-0x22 특수문자
- 0x23 숫자 및 영문자
- 0x24-0x25 히라가나, 가타카나
- 0x26-0x27 키릴문자, 그리스문자
- 0x28 표 그리기 부호
- 0x29 Undefined
- 0x30-0x4F 제1한자
- 0x50-0x78 제2한자
- 0x79-0x7E Undefined
이러한 매핑방법이 JIS C 6226으로 표준화 되었으며, 차후 JIS X 0208로 이름이 바뀌게 된다.
자 문제. 새롭게 JIS-C-6226 표준이 나왔는데, 이걸 쓰려고 보니 기존의 JIS-C-6220 표준과 전혀 호환이 되지 않는다. 애당초 ASCII 영역(ISO/IEC 646 영역)까지도 덮어버리도록 설계가 되었기 때문에, 이걸 생짜로 쓰면 ASCII 파일과도 호환되지 않는 참담한 상황이 되는 것이다.
JIS-C-6226 표준에서는 호환성을 위해 3가지 매핑 방법에 7비트, 8비트 구분해서 총 6가지 매핑 방법을 정의하고 있다. 물론 이 중 어느것도 IANA에서는 웹 표준 인코딩 방법으로 채택되지 않았다...
- 쌩으로 JIS-C-6226만 쓰는 모드. 7, 8비트 공히 GL영역에 한자집합을 매핑. GR영역은 사용하지 않는다.
- ISO/IEC 646 (IRV) 호환 모드. GL영역에 IRV를 매핑, GR영역에 한자집합을 매핑한다. 7비트 통신을 쓸 때는 SO/SI 제어문자를 이용하여 GL영역의 매핑을 IRV와 한자집합 사이에서 전환할 수 있다.
- LATIN 호환 모드. GL 영역에 JIS-C-6220의 GL영역을 매핑, GR영역에 한자집합을 매핑한다. 7비트 통신은 SO/SI 사용.
여하튼, 위 방법들은 기존 JIS-C-6220의 GR영역 반각 가타카나 매핑을 깡그리 무시하고 있으므로, 구 표준과 호환성이 없다. 구 표준을 버리고 갈아엎느냐, 아니면 호환성을 위해 어떻게든 때려박느냐의 기로에서 개발자들은 결국 호환성을 선택했다. Shift-JIS라고 하여, JIS-C-6226의 94×94 테이블을 JIS-C-6220의 GR 영역 남은 공간에 때려박는 방법을 고안해 낸 것이다.
JIS-C-6220 표준에서 비어 있는 공간은 0x81-0x9F CR 영역과, 0xE0-0xFE GR 영역의 일부분으로 64개 값을 저장할 수 있다. 이에 맞추어, 94×94 테이블을 조금 비틀어 47×188로 바꾸고 잘 때려박으면 되겠거니... 라는게 Shift-JIS의 기본 발상이다. JIS 테이블의 선행 바이트의 1비트를 후행 바이트로 밀어냈으므로, Shift-JIS라고 명명된 것이다.
이제 선행 바이트는 47개 값을 가지게 되므로 CR 영역과 GR 영역의 빈 공간에 매핑하게 된다. 후행 바이트는 188개 값을 저장해야 하므로, CR+GR 뿐만 아니라 GL 영역까지 침범, 0x40-0x7E, 0x80-0xFE 영역을 사용한다.
그 결과물은 다음과 같다. 이미지는 위키피디아 Shift-JIS 문서에서 가져왔다.
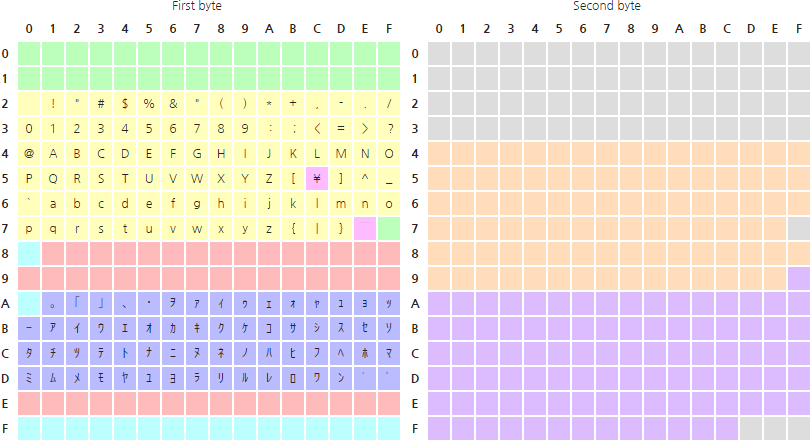
참고로 일본 휴대폰의 그림문자(Emoji)는 선행 바이트에서 사용하지 않는 0xF0-0xFE 영역을 임의로 사용하는 것이다.
자, 어떻게 2바이트 안에 기존의 JIS-C-6220 반각 가타카나와 JIS-C-6226 한자집합을 모두 때려박는데 성공하였다. Shift-JIS는 JIS-C-6226이 JIS-X-0208로 개정되면서 Appendix로 편입되었고, IANA에서 Shift_JIS로 승인되었다.
이게 잘 되면 좋겠는데... 검색 및 정렬에 취약하다거나 하는 문제는 넘어가고, 호환성 문제가 또 터져나오게 된다. 바로 후행 바이트에서 0x5C REVERSE SOLIDUS를 새롭게 매핑하고 있다는 점이다. 이 문자는 윈도우에서 파일 경로를 쓸 때 디렉터리 구분자로 사용한다. 이게 후행 바이트에서 다른 의미로 사용되다보니, Shift-JIS를 이해 못하는 프로그램에서 파일이름 해석이 완전히 파손되는 문제를 야기하는 것이다.
다행히 0x2F SOLIDUS는 오버랩 되지 않아 xNIX 계열에서는 문제가 없다. 윈도우 사용자만 고통받는다. 유니코드에서는 이런 문제가 없지만, 갈라파고스 국가답게 여전히 Shift_JIS는 인터넷에서 1% 넘게 사용되고 있다. 일본어 윈도우 표준 코드페이지이기도 하고.
물론 일본어 인코딩이 Shift-JIS만 있는 것도 아니다. xNIX 계열에서 사용했던 EUC-JP라는 인코딩 방식도 남아있다. 이 규격은 JIS-X-0208의 8비트 LATIN 호환모드를 기본으로 하되, JIS-X-0201 GR영역은 0x8E 0x??로 2바이트 매핑하게 된다. JIS-X-0212 확장 한자표까지 지원하지만, Shift-JIS에 밀려서 거의 사용하지는 않는다.
참고로 비슷한 문제가 한국어 코드페이지에서도 발생할 뻔 했으나... Shift-JIS에서 피똥싸는걸 본 마소에서 이런 설계를 회피하게 된다.
KS-C-5601 (개정 KS-X-1001)은 94x94 테이블에 한글 완성형 2350자를 정의하고 있다. 한글 완성형-조합형 논란은 넘어가자. EUC-KR에서는 GL영역에는 KS-C-5636(개정 KS-X-1003)을, GR영역에는 KS-C-5601을 매핑하여 완성형을 구현하고 있다. KS-C-5636은 ASCII에서 0x5C 백슬래시를 한국 원 표시로 바꾼 것이다. 그냥 ASCII로 취급해도 아무 문제 없다.
여하튼, 한글 채움문자를 사용하거나 부속서 3의 상용 조합형을 이용하여 추가 한글을 표현할 수 있으나, 아무도 안 쓴다. 마소에서 EUC-KR을 확장한 CP949를 정의하면서 그냥 현대에 사용되는 추가 한글 8822자를 다 때려박았기 때문이다. 이 때 CP949는 후행 바이트에서 문제가 되는 특수문자를 제외함으로써 0x5C 문제를 해결하였다. 구체적으로, 후행 바이트의 범위를 0x41-0x5A [A-Z], 0x61-0x7A [a-z], 0x81-0xFE로 제한하고 있다. 덕분에 처리가 더 골룸해지긴 하지만 우리가 신경쓸 부분은 아니다.
여하튼 이런 문제는 유니코드 도입하면 다 사라질 문제이긴 한데, 유니코드 초기 버전에서는 거꾸로 한글 영역에서 좀 병신짓이 있긴 했다.
유니코드 1.0에서는 한글 완성형 2350글자만 포함했으나, 6천자 정도 확장하더니 유니코드 2.0에서는 아예 코드페이지를 대거 이주했다. 현재 한글 완성형은 유니코드 BMP 끝부분에 위치하는데, 한중일 통합 한자 외에 단독 언어로 11172글자를 혼자 점유하기 때문이다 (...) 또한 BMP 끝부분에 위치하는 이유도 이렇게 글자 추가에 따른 이주의 흔적이다.